▶ 컬렉션(collection)
- 여러 객체(데이터)를 모아놓은 것을 의미
▶ 프레임웍(framework)
- 표준화, 정형화된 체계적인 프로그래밍 방식
▶ 컬렉션 프레임웍(collection framework)
- 컬렉션(다수의 객체)을 다루기 위한 표준화된 프로그래밍 방식
- 컬렉션을 쉽고 편리하게 다룰 수 있는 다양한 클래스를 제공(저장, 삭제, 검색, 정렬)
- java.util패키지에 포함. JDK1.2부터 제공함.
▶ 컬렉션 클래스(collection class)
- 다수의 데이터를 저장할 수 있는 클래스(예- Vector,ArrayList,HashSet)
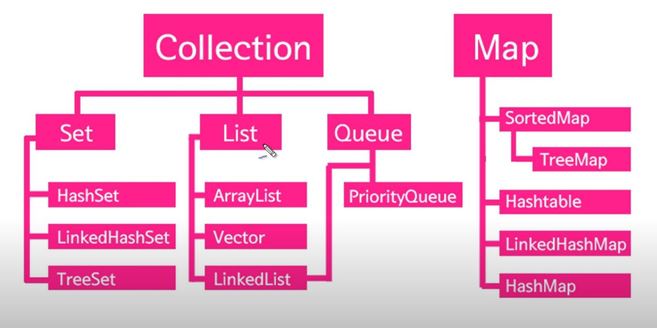
⦁ 컬렉션 프레임웍의 핵심 인터페이스
List(순서O, 중복 허용)
Set(순서X, 중복 불가능)
Map(순서X, 키는 중복 불가능, 값은 중복 허용) / 키=id, 값(value)=비밀번호 라고 생각

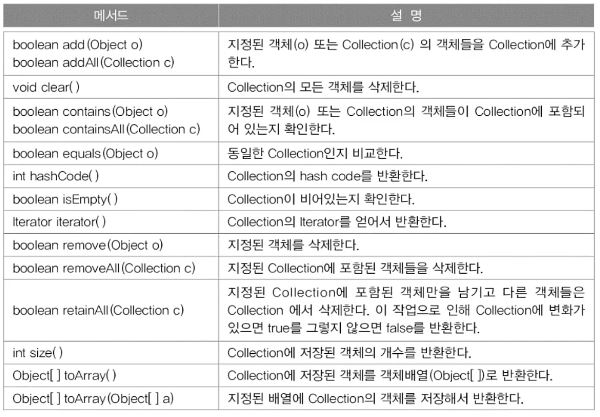
⦁ Collection인터페이스의 메소드
⦁ List 인터페이스 – 순서O, 중복O
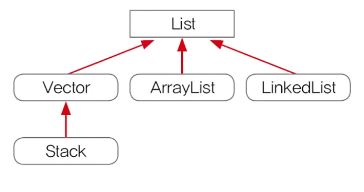

List는 Collection 인터페이스의 자손이므로 Collection의 메소드를 가지고 있음.
⦁ Set인터페이스 – 순서X, 중복X
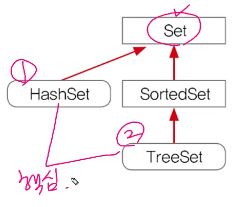
* Set인터페이스의 메소드는 Collection인터페이스와 동일
* 집합과 관련된 메소드(Collection에 변화가 있으면 true, 아니면 false를 반환)

⦁ Map인터페이스 – 순서X,중복(키X,값O)
- Map 인터페이스의 메소드
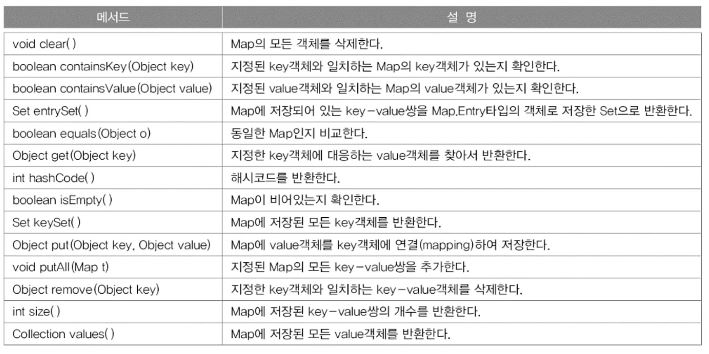
keySet()과 values()로 각각 키와 값을 뽑아낼 수 있고 EntrySet()으로 Entry(키와 값의 쌍)
를 뽑아내서 Set으로 반환할 수 있음.
⦁ ArrayList
- ArrayList는 기존의 Vector를 개선한 것으로 구현원리와 기능적으로 동일
ArrayList와 달리 Vector는 자체적으로 동기화처리가 되어 있다.
- List인터페이스를 구현하므로, 저장순서가 유지되고 중복을 허용한다.
- 데이터의 저장공간으로 배열을 사용한다(배열기반)
-> 모든 종류의 객체를 저장할 수 있다.
⦁ ArrayList의 메소드
생성자)
ArrayList()
ArrayList(Collection C)
ArrayList(int initicalCapacity) // 배열의 길이 설정
기능별 메소드)
-저장-
boolean add(Object o) // 객체를 추가, 성공하면 true 실패는 false
void add(int index, Object element) // 객체를 특정위치에 저장
boolean addAll(Collection c) // 컬렉션의 요소를 그대로 저장
boolean addAll(int index, Collection c) // 컬렉션의 요소를 특정 위치에 저장
-삭제-
boolean remove(Object o) // 객체를 삭제
Object remove(int index) // 특정 위치에 있는 객체 삭제
boolean removeAll(Collection c) // 해당 컬렉션에 있는 객체를 삭제
void clear() // 모든 객체 삭제
-검색-
int indexOf(Objecct o) // 객체가 몇 번째 인덱스에 있는지 검색, 못 찾으면 –1
int lastIndexOf(Object o) // 오른쪽 끝에서부터 검색, indexOf와 같은 기능
boolean contains(Object o) // 객체가 존재하는지, 있으면 true
Object get(int index) // 객체를 읽기
Object set(int index, Object element) // 특정 위치에 있는 객체를 다른 객체로 변경
-기타-
List subList(int fromIndex, int toIndex)
Object[] toArray() // ArrayList의 객체 배열을 반환
Object[] toArray(Object[] a)
boolean isEmpty() // 비어있는지 확인
void trimToSize() // 빈 공간 제거
int size() // 저장된 객체의 개수를 반환
ex)
import java.util.ArrayList;
import java.util.Collections;
public class Ex11_1 {
static void print(ArrayList list1, ArrayList list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
public static void main(String[] args) {
ArrayList list1 = new ArrayList(10);
// ArrayList에는 객체만 저장가능
// autoboxing에 의해 기본형이 참조형으로 자동 변환
list1.add(5);
list1.add(4);
list1.add(new Integer(2));
list1.add(new Integer(0));
list1.add(new Integer(1));
list1.add(new Integer(3));
// ArrayList(Collection c) 생성자를 이용해서 새로운 ArrayList를 만듦.
ArrayList list2 = new ArrayList(list1.subList(1,4));
print(list1, list2);
// Collection은 인터페이스, Collections는 유틸 클래스이다. (s의 차이...)
Collections.sort(list1);
Collections.sort(list2);
print(list1, list2);
System.out.println("list1.containsAll(list2) : " +list1.containsAll(list2));
// list1이 list2의 모든 요소를 포함하고 있는지, 포함하면 true
list2.add("B");
list2.add("C");
list2.add(3, "A");
print(list1, list2);
list2.set(3, "AA");
print(list1, list2);
list1.add(0, "1"); // "1"을 추가
// indexOf()는 지정된 객체의 위치(인덱스)를 알려준다.
System.out.println("index="+ list1.indexOf(new Integer(1))); // Integer 1의 index
System.out.println("index="+ list1.indexOf("1")); // String "1"의 index
print(list1, list2);
// list1.remove(1); // index가 1인 객체를 삭제
list1.remove(new Integer(1)); // 숫자 1을 삭제
print(list1, list2);
System.out.println("list1,retainAll(list2) : "+list1.retainAll(list2));
// list1에서 list2와 겹치는 부분만 남기고 나머지는 삭제한다.
print(list1,list2);
// list2에서 list1에 포함된 객체들을 삭제한다.
for(int i=list2.size()-1; i>=0; i--) {
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
}
}
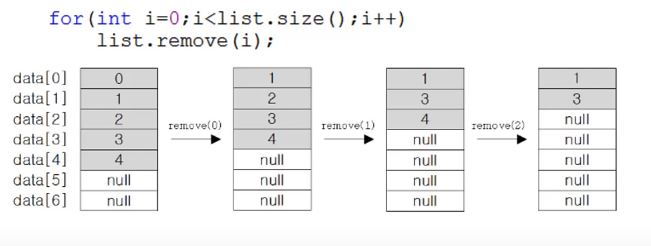
⦁ ArrayList에 저장된 객체의 삭제과정
1) ArrayList에 저장된 첫 번째 객체부터 삭제하는 경우(배열 복사 발생)
앞의 객체가 삭제되면서 뒤의 객체를 복사해서 앞으로 이동하게 됨.
성능상으로도 안 좋고 삭제가 완벽하게 되지 않을수도 있음.
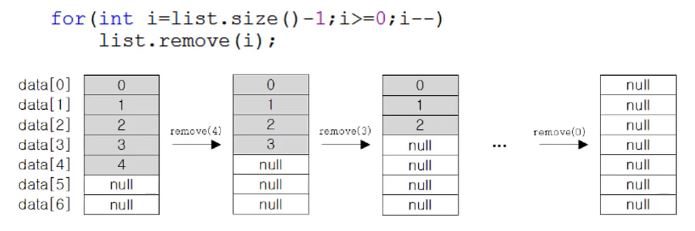
2) ArrayList에 저장된 마지막 객체부터 삭제하는 경우(배열 복사 발생안함)
뒤에서부터 삭제하면 객체가 복사되지 않아서 작업속도도 빠르고 모든 객체를 완벽하게 삭제할 수 있음. (★ 잘 기억해두는게 좋음 ★)
⦁ 배열의 장단점
▶ 장점 : 배열은 구조가 간단하고 데이터를 읽은 데 걸리는 시간(접근시간, access time)이 짧다.
▶ 단점 : 크기를 변경할 수 없다.(실행중에)
- 크기를 변경해야 하는 경우 새로운 배열을 생성 후 데이터를 복사해야함.
* 더 큰 배열 생성->기존 데이터 복사->참조 변경
- 크기 변경을 피하기 위해 충분히 큰 배열을 생성하면, 메모리가 낭비됨.
▶ 단점 2 : 비 순차적인 데이터의 추가, 삭제에 시간이 많이 걸린다.
- 데이터를 추가하거나 삭제하기 위해, 다른 데이터를 옮겨야 함.
- 그러나 순차적인 데이터 추가(끝에 추가)와 삭제(끝부터 삭제)는 빠르다(데이터 이동이 없기 때문)
⦁ LinkedList – 배열의 단점을 보완
- 배열(연속적임)과 달리 링크드 리스트는 불연속적으로 존재하는 데이터를 연결(link)
▶ 데이터의 삭제 : 단 한번의 참조변경만으로 가능
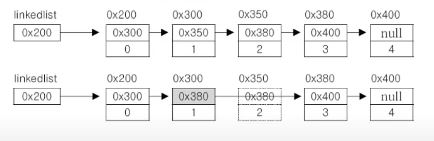
(개별 요소를 Node라고 함)
class Node {
Node next; // 다음 노드
Object obj; // 데이터
}
▶ 데이터의 추가 : 한 번의 Node객체 생성과 두 번의 참조변경만으로 가능
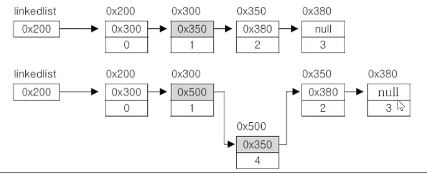
▶ LinkedList – 연결리스트. 데이터 접근성이 나쁨
첫 번째 요소는 두 번째 요소의 주소만 알고 있기 때문에 한 번에 건너뛰는 것이 불가능함
▶ 더블리 링크드 리스트(doubly linked list) - 이중 연결리스트, 접근성 향상
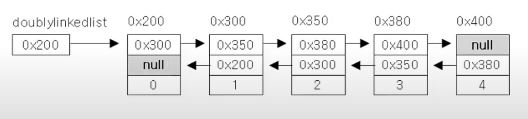
class Node {
Node next; // 다음 노드
Node previous; // 이전 노드
Object obj; // 데이터
}
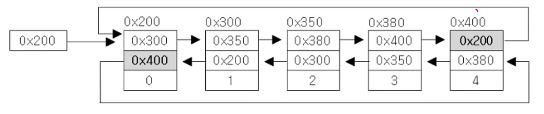
▶ 더블리 써큘러 링크드 리스트(doubly circular linked list) - 이중 원형 연결리스트
⦁ ArrayList(배열기반) vs. LinkedList(연결기반) – 성능 비교
순차적으로 데이터를 추가/삭제 – ArrayList가 빠름
비순차적으로 데이터를 추가/삭제 – LinkedList가 빠름
접근시간(access time) - ArrayList가 빠름

이어서...
출처 - 유튜브 남궁성의 정석코딩 [자바의 정석 - 기초편]
'Java > Java의 정석' 카테고리의 다른 글
| 220322 Java - Chapter.11 Collections Framework Part.3 (0) | 2022.03.23 |
|---|---|
| 220321 Java - Chapter.11 Collections Framework Part.2 (0) | 2022.03.21 |
| 220316 Java - Chapter 10. 날짜와 시간 & 형식화 (0) | 2022.03.17 |
| 220315 Java - Chapter 9. java.lang패키지와 유용한 클래스 (0) | 2022.03.15 |
| 220314 Java - Chapter 8. 예외 처리(이어서 마무리) (0) | 2022.03.14 |